一、前言
当开发好MapReduce程序后,应该如何运行它来验证程序正确性呢?
本文介绍三种常见的运行MapReduce程序的模式,包括:
- 在集群上运行
- 在Windows本地运行
- 从Windows本地提交集群运行
二、在集群上运行
这是最常用的运行方式,它是在正式生产环境运行的一种方式。
我们需要将MapReduce程序(包括Mapper,Reducer,包含main方法等相关的类)打成jar包,再将jar包拷贝到集群上,最后运行hadoop jar或yarn jar命令执行。
如:
使用hadoop jar运行:
$ hadoop jar hadoop-test-0.0.1-SNAPSHOT.jar com.yglong.hadoop.mapred.wordcount.WordCount /data/wc/input /data/wc/output使用jarn jar运行,其实与hadoop jar是完全一样的:
$ yarn jar hadoop-test-0.0.1-SNAPSHOT.jar com.yglong.hadoop.mapred.wordcount.WordCount /data/wc/input /data/wc/output运行后查看输出结果:
$ hadoop fs -ls /data/wc/output
Found 2 items
-rw-r--r-- 2 bigdata supergroup 0 2020-08-03 05:25 /data/wc/output/_SUCCESS
-rw-r--r-- 2 bigdata supergroup 36 2020-08-03 05:25 /data/wc/output/part-r-00000三、在Windows本地运行
我们可以直接在Windows本机运行MapReduce程序,这种方式特别适用于开发阶段,主要方便在开发map和reduce等方法时调试代码,甚至可以打断点跟踪框架内部运行情况。使用这种方式,再也不需要每次修改代码后都打jar包,然后拷贝到集群,再运行程序,而且只能通过log来调试程序这么麻烦了。
1. 安装并配置本地hadoop环境
要在Windows本地运行MapReduce程序,需要先在本地安装Hadoop。
在Windows上安装hadoop,与在Linux上类似,从官网下载hadoop压缩包,解压到某个本地目录即可。
然后需要设置HADOOP_HOME,JAVA_HOME环境变量。并在Path环境变量中添加:
%HADOOP_HOME%\bin;%JAVA_HOME%\bin;2. 安装winutils
要在Windows上使用hadoop,还需要做一个与Linux上不一样的特殊设置。那就是安装winutils。
如果不做这一步,当运行MapReduce程序时,你会遇到类似如下的报错:
2020-08-03 13:59:43,264 [myid:] - WARN [main:Shell@693] - Did not find winutils.exe: {}
java.io.FileNotFoundException: Could not locate Hadoop executable: C:\ylong\tool\hadoop-3.2.1\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems
at org.apache.hadoop.util.Shell.getQualifiedBinInner(Shell.java:619)
at org.apache.hadoop.util.Shell.getQualifiedBin(Shell.java:592)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:689)
at org.apache.hadoop.util.GenericOptionsParser.preProcessForWindows(GenericOptionsParser.java:520)
at org.apache.hadoop.util.GenericOptionsParser.parseGeneralOptions(GenericOptionsParser.java:571)
at org.apache.hadoop.util.GenericOptionsParser.<init>(GenericOptionsParser.java:174)
at org.apache.hadoop.util.GenericOptionsParser.<init>(GenericOptionsParser.java:156)
at com.yglong.hadoop.mapred.wordcount.WordCount.main(WordCount.java:49)首先,从下载地址下载winutils。
注意:
需要下载的
winutils的版本必须与安装的hadoop版本一致。例如我本地安装的hadoop 3.2.1,所以需要下载hadoop 3.2.1对应的winutils
下载所有文件(包括winutils.exe, hadoop.dll等)后,全部拷贝到%HADOOP_HOME%\bin目录下。
3. 引入hadoop client依赖
本地hadoop环境配置好后,就可以在本地开发MapReduce程序了。
首先,需要引入hadoop依赖包,在pom.xml中添加:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoopVersion>3.2.1</hadoopVersion>
</properties>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoopVersion}</version>
</dependency>4. 日志配置
如果要在本地集成环境如IDEA中看到MapReduce执行日志,需要配置日志。
在pom.xml中添加slf4j的实现依赖,如:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>然后在src/main/resources下添加log4j.properties文件,配置日志,例如:
hadoop.root.logger=INFO, CONSOLE
hadoop.console.threshold=INFO
log4j.rootLogger=${hadoop.root.logger}
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${hadoop.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} %-5p [%C]: %m%n设置日志后,在本地运行MapReduce程序时,就可以在本地也看到类似在集群上运行时输出的日志信息了。
5. 使用本地文件路径
默认情况下,如果在代码中不做任何设置,MapReduce程序是以local模式运行的。
当以local模式运行时,程序使用的输入输出文件或目录都是本地文件或目录,而不是HDFS上的文件或目录。所以在为程序提供输入输出文件路径时,需要指定Windows本地路径。如:
Path infile = new Path("C:\\tmp\\data\\wc\\input");
FileInputFormat.addInputPath(job, infile);
Path outfile = new Path("C:\\tmp\\data\\wc\\output");
if (outfile.getFileSystem(conf).exists(outfile)) {
outfile.getFileSystem(conf).delete(outfile, true);
}
FileOutputFormat.setOutputPath(job, outfile);为了不在程序中写死路径,也可以通过参数提供输入输出文件路径,这样就可以在代码中通过参数动态获取了。
可以使用GenericOptionsParser工具类,它可以自动将-D的参数设置到Configuration对象中。
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
Path infile = new Path(otherArgs[0]);
FileInputFormat.addInputPath(job, infile);
Path outfile = new Path(otherArgs[1]);
if (outfile.getFileSystem(conf).exists(outfile)) {
outfile.getFileSystem(conf).delete(outfile, true);
}
FileOutputFormat.setOutputPath(job, outfile);在运行程序时,可以提供程序参数,如下,提供了本地路径作为输入和输出路径:
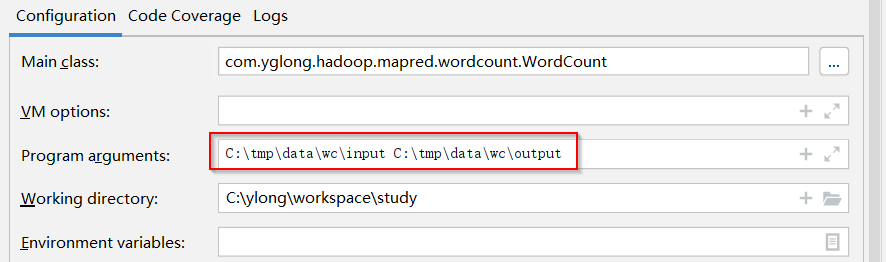
运行程序后,可以看到结果文件也输出在了指定的本地目录下:

6. 其他设置
如果为了在本地提交到集群运行MapReduce程序而在classpath中(如src/main/resources中)添加了集群的配置文件(core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml)。这种情况下,hadoop客户端会优先读取配置文件,从而会尝试将程序提交到配置文件中指定的集群上去运行。
而当你提供的输入输出路径为本地路径时,你会收到类似如下的报错:
Exception in thread "main" java.lang.IllegalArgumentException: Pathname /C:/tmp/data/wc/output from C:/tmp/data/wc/output is not a valid DFS filename.
at org.apache.hadoop.hdfs.DistributedFileSystem.getPathName(DistributedFileSystem.java:236)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1576)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1573)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1588)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1683)
at com.yglong.hadoop.mapred.wordcount.WordCount.main(WordCount.java:89)这种情况下,如果想强制在本地运行程序,可以设置另外两个配置项:
Configuration conf = new Configuration();
// 如果在windows本地执行MR程序,必须将mapreduce.framework.name设置为local
conf.set("mapreduce.framework.name", "local");
// 有些版本也需要将fs.defaultFS设置为file:///,让MR程序查找本地路径,而不是HDFS路径。
// 经测试,hadoop-3.2.1必须设置
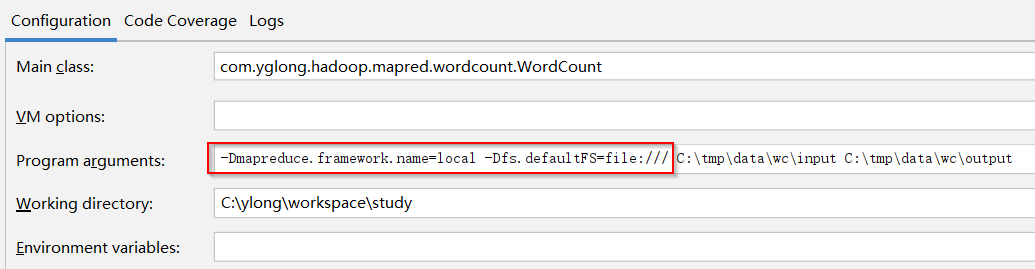
conf.set("fs.defaultFS", "file:///");当然为了不在程序中写死,也可以通过命令参数-D提供这两个配置项:
-Dmapreduce.framework.name=local -Dfs.defaultFS=file:///如图:
综上所述,其实要在本地成功运行MapReduce程序,还是有不少坑的,本地环境的配置挺不少的。希望本文能帮助各位少走点弯路,搞定这些配置后,以后就可以开心的在本地开发和调试MapReduce程序了。
四、从Windows本地提交集群运行
当在Windows本地运行MapReduce程序时,默认是在本地的hadoop环境中运行的。
你是否也在想能否直接在本地将程序提交到集群中去跑,而不用打jar再手动拷贝到集群上去运行呢?
答案是肯定的。
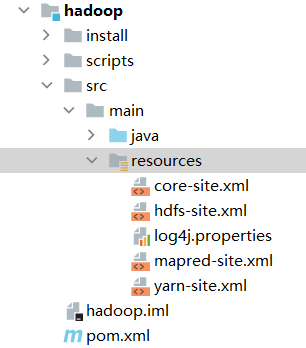
要在Windows本地将程序提交到远程的集群中运行,只需要先将集群的配置文件添加到本地classpath中,如添加到src/main/resources目录下。
将集群上任一节点的$HADOOP_HOME/etc/hadoop目录下的core-site.xml,hdfs-site.xml, yarn-site.xml, mapred-site.xml拷贝到classpath中。
但是,这还不够,以下是笔者在这个过程中遇到的一系列问题以及解决办法,最终还是成功搞定了从本地提交集群运行这一模式。
1. 问题1
报错信息如下:
2020-08-03 15:02:40,613 INFO [org.apache.hadoop.mapreduce.Job]: Job job_1596433378472_0001 failed with state FAILED due to: Application application_1596433378472_0001 failed 2 times (global limit =5; local limit is =2) due to AM Container for appattempt_1596433378472_0001_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2020-08-03 07:02:37.497]Exception from container-launch.
Container id: container_1596433378472_0001_02_000001
Exit code: 1
[2020-08-03 07:02:37.561]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
/bin/bash: line 0: fg: no job control
[2020-08-03 07:02:37.561]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
/bin/bash: line 0: fg: no job control
For more detailed output, check the application tracking page: http://bigdata02:8088/cluster/app/application_1596433378472_0001 Then click on links to logs of each attempt.
. Failing the application.
2020-08-03 15:02:40,630 INFO [org.apache.hadoop.mapreduce.Job]: Counters: 0如果遇到如上的类似/bin/bash之类的错误,那就是忘记了配置支持跨平台的参数:
// 如果从windows本地提交MR程序到集群运行,必须设置mapreduce.app-submission.cross-platform为true,支持跨平台
conf.set("mapreduce.app-submission.cross-platform", "true");而这个参数默认值是false,因此我们需要手动设置为true。
2. 问题2
报错信息如下:
2020-08-03 15:21:09,920 INFO [org.apache.hadoop.mapreduce.JobSubmitter]: Cleaning up the staging area /opt/software/hadoop/yarn/staging/ylong/.staging/job_1596438997159_0003
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=ylong, access=EXECUTE, inode="/opt":bigdata:supergroup:drwx------
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:315)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:242)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1879)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1863)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkOwner(FSDirectory.java:1808)
at org.apache.hadoop.hdfs.server.namenode.FSDirAttrOp.setPermission(FSDirAttrOp.java:63)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.setPermission(FSNamesystem.java:1905)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.setPermission(NameNodeRpcServer.java:876)HDFS目录权限问题。一般是因为在集群上以其他用户运行过MapReuce程序,从而以其他用户在HDFS中创建了yarn相关的目录。而在Windows上执行时,是以计算机用户名来运行的,因此对于HDFS上这个已创建的目录,有可能是没有访问权限的。
暴力点的解决办法,直接把报错的目录设置为777。从上面的异常中,可以看到报错的目录是/opt,所以,直接将/opt和子目录全部设置为777即可:
$ hadoop fs -chmod -R 777 /opt3. 问题3
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.yglong.hadoop.mapred.wordcount.WordCount$TokenizerMapper not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2638)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:187)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:759)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:347)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)这个错很明显了,运行时找不到自定义的Mapper类: TokenizerMapper。
在本地远程提交集群运行时,必须设置要提交的程序jar包,如下:
job.setJar("C:\\ylong\\workspace\\study\\hadoop\\target\\hadoop-test-0.0.1-SNAPSHOT.jar");这个jar包需要在本地先打出来,如使用maven打包。其实就是将我们自己开发的所有类,如Mapper和Reducer类打包到jar里,因为这些类在集群中运行时需要被用到。
因此,我们总结一下,要想从本地提交MapReduce程序到集群运行,需要做如下几个事情:
- 拷贝集群配置文件到
classpath - 设置
mapreduce.app-submission.cross-platform为true - 将自定义类打成
jar包,并设置到job里 - 如果遇到
HDFS目录权限问题,设置目录权限



