本教程将训练一个神经网络模型来对衣服图片进行分类,比如运动鞋和衬衫。这是一个完整的机器学习示例,完成本教程后,你就可以在此基础上使用TensorFlow处理实际的分类问题。你也将看到使用TensorFlow 2.0处理此类问题是多么的直观和简单。
本教程同样会使用keras的高级API,在TensorFlow中构建和训练模型。从TensorFlow 2.0开始,使用keras高级API进行编程已经成为首选,因为它从更高层次抽象了底层API,从而极大地简化了开发。
首先,导入本教程将使用的库:
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)2.0.0-alpha0导入数据集
本教程将使用Fashion MNIST数据集,其中包含10个类别,以及70000张灰度图片。图片显示的是低分辨率(28×28像素)的衣服,如下图所示:

Fashion MNIST数据集是经典MNIST手写数字数据集的替代——现在通常被用作计算机视觉机器学习的Hello, World程序。经典MNIST数据集包含手写数字(0、1、2等)的图片,其格式与我们将在这里使用的衣服图片相同。
本教程之所以使用Fashion MNIST数据集,因为对这个数据集的分类比普通MNIST手写数字数据集更具挑战性。这两个数据集都相对较小,一般用于验证算法,它们都是用于测试和调试代码的一个比较好的起点。
我们将使用60000张训练图片来训练神经网络模型,并使用10000张图片来评估模型对图片分类的准确率。我们可以直接从TensorFlow获取Fashion MNIST,以下代码从TensorFlow导入和加载Fashion MNIST数据:
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 2us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 11s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
8192/5148 [===============================================] - 0s 1us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 2s 1us/step加载的数据集包含4个Numpy数组:
train_images和train_labels数组是训练数据集,也就是用来训练模型的数据。test_images和test_labels数组是测试数据集,模型将使用它们进行测试。
数据集中的图片都是28x28的NumPy数组,像素值从0到255。标签是一个整数数组,值从0到9,对应于图片所代表的服装类别:
| 标签 | 所代表的服装类别 |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
每张图片都映射到了一个0到9的数字标签,而没有映射到类别名称。由于数据集中没有包含各个类别的名称,所以我们可以事先将它们存储起来,以便稍后画图时使用:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']探索数据
在训练模型之前,让我们先研究一下数据集。如下所示,训练集中有60000张图像,每张图像表示为28x28像素:
print(train_images.shape)(60000, 28, 28)同样,训练集中有60000个标签:
print(len(train_labels))60000每个标签都是0到9之间的整数:
print(train_labels)[9 0 0 ... 3 0 5]测试集中有10000张图片,同样,每张图片用28×28像素表示:
print(test_images.shape)(10000, 28, 28)测试集包含10000张图片的标签:
print(len(test_labels))10000标签值同样是0到9之间的整数:
print(test_labels)[9 2 1 ... 8 1 5]预处理数据
在训练网络之前,必须对数据进行预处理。如果你检查训练集中的第一张图片,你会发现像素值在0到255之间:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()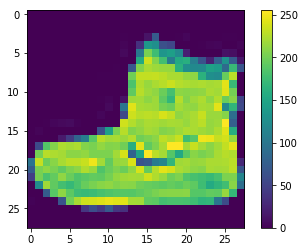
在将这些值输入神经网络模型之前,我们将这些值缩小到0到1的范围。为此,我们将值除以255。值得注意的是,训练集和测试集必须以相同的方式进行预处理:
train_images = train_images / 255.0
test_images = test_images / 255.0为了验证数据的格式是否正确,以及我们是否准备好构建和训练神经网络模型,让我们显示训练集中的前25张图片,并在每张图片下面显示类别名称。
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
构建模型
当我们构建神经网络时,需要对模型的层进行配置,然后对模型进行编译。
配置模型层(layer)
一个神经网络的基本构件是层(layer)。层从输入的数据中提取表示(representation),并希望这些被提取的表示对正在处理的问题具有意义。
大多数深度学习都是由一系列简单的层次链组成的。如tf.keras.layers.Dense的大多数层都将在网络的训练中学习到参数。我们依然使用Sequential层叠模型构建一个全连接网络:
model = keras.Sequential([
keras.layers.Flatten(input\_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])网络的第一层是tf.keras.layers.Flatten,该层将图像的格式从二维数组(28×28像素)转换为一维数组(28 * 28 = 784像素)。将这个层看作是将图像中的像素行分解并排列起来。这一层没有需要学习的参数,它只重新格式化数据。
当图片像素被平铺后,网络由两个tf.keras.layers.Dense紧凑层组成。它们是紧密相连的,或者说全连接层。第一个Dense层有128个节点(或神经元),第二个(也是最后一个)Dense层是一个10个节点的softmax 层,它返回一个由10个概率值组成的数组,其和为1。每个节点包含一个评分值,表示当前图片属于10个类别中的一个的概率。
编译模型
在模型准备好训练之前,它需要一些设置,这些设置是在模型的编译阶段完成的:
- 指定
损失函数(Loss function):测量模型在训练过程中有多精确。我们需要最小化这个函数来“引导”模型朝着正确的方向。 - 指定
优化器(Optimizer) :这是模型根据所看到的数据及其损失函数更新模型参数的方法。 - 指定
度量参数(Metrics) :用于监测训练和测试步骤。下面的例子使用准确率(accuracy),即被正确分类的图片比例。
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])训练模型
训练神经网络模型需要以下步骤:
- 将训练数据提供给模型。在本例中,训练数据为
train_images和train_labels数组。 - 模型不断学习,将图像和标签关联起来。
- 使用模型对测试集做出预测,在这个例子中,测试集是
test_image数组,我们需要验证预测结果与test_labels数组中的标签是否匹配。
要对模型进行训练,我们需要调用fit函数——之所以该函数叫fit,是因为它将模型与训练数据进行匹配:
model.fit(train_images, train_labels, epochs=10)Epoch 1/10
60000/60000 [==============================] - 3s 52us/sample - loss: 0.4966 - accuracy: 0.8245
Epoch 2/10
60000/60000 [==============================] - 3s 44us/sample - loss: 0.3762 - accuracy: 0.8634
Epoch 3/10
60000/60000 [==============================] - 3s 49us/sample - loss: 0.3370 - accuracy: 0.8776
Epoch 4/10
60000/60000 [==============================] - 3s 49us/sample - loss: 0.3129 - accuracy: 0.8853
Epoch 5/10
60000/60000 [==============================] - 3s 45us/sample - loss: 0.2938 - accuracy: 0.8914
Epoch 6/10
60000/60000 [==============================] - 3s 44us/sample - loss: 0.2780 - accuracy: 0.8972
Epoch 7/10
60000/60000 [==============================] - 3s 44us/sample - loss: 0.2658 - accuracy: 0.9014
Epoch 8/10
60000/60000 [==============================] - 3s 44us/sample - loss: 0.2550 - accuracy: 0.9050
Epoch 9/10
60000/60000 [==============================] - 3s 43us/sample - loss: 0.2454 - accuracy: 0.9079
Epoch 10/10
60000/60000 [==============================] - 3s 44us/sample - loss: 0.2364 - accuracy: 0.9111
<tensorflow.python.keras.callbacks.History at 0x17e09828>在模型训练过程中,损失值与准确率这两个指标会被显示。可以看到最终该模型对训练数据的准确率达到了约0.88(88%)。
评估模型准确率
接下来,我们看看模型在测试数据集上的性能:
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('\nTest accuracy: ', test_acc)10000/10000 [==============================] - 0s 28us/sample - loss: 0.3420 - accuracy: 0.8845
Test accuracy: 0.8845结果表明,测试数据集的准确率略低于训练数据集的准确率,这表示过拟合了。过拟合是指机器学习模型在新的、以前没见过的输入上的表现比在训练数据上差。
使用模型进行预测
通过已训练的模型,我们可以用它来对新的图片进行预测。
predictions = model.predict(test_images)这里,我们用模型预测了测试集中的所有图片,让我们看一下第一个图片的预测结果:
predictions[0]array([1.9848918e-07, 6.2967965e-06, 1.2487946e-07, 4.5386751e-06,
1.3287071e-06, 3.8301453e-02, 5.6206454e-07, 6.0179353e-02,
6.4673060e-07, 9.0150553e-01], dtype=float32)每个图片的预测结果都是由10个数字组成的数组,它们表示了图片属于10个类别中的每个类别的置信度。我们可以看看哪个标签的置信度最高:
np.argmax(predictions[0])9因此,模型最确信的标签是9,class_names[9] 是一双踝靴(ankle boot)。我们检查一下第一个图片的测试标签,也是9,因此模型正确地预测了该图片的分类:
print(test_labels[0])9我们可以通过画图来查看完整的10个类别的预测值。
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel('{} {:2.0f}% ({})'.format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color='#777777')
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')让我们看看第1张图片(索引为0)的预测结果和预测数组:
i = 0
plt.figure(figsize=(6, 3))
plt.subplot(1, 2, 1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1, 2, 2)
plot_value_array(i, predictions, test_labels)
plt.show()
再随机看看某个图片:
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
plt.show()
我们也可以画出更多的图片。正确的预测标签是蓝色的,错误的预测标签是红色的。预测结果数组中的数字表示预测为某标签的百分比(满分为100),比例越高,表明模型认为图片属于某个类别的可能性越大。请注意,即使置信度非常高,也不代表预测结果是对的。
num_rows = 5
num_cols = 3
num_images = num_rows * num_cols
plt.figure(figsize=(2*2*num_cols, 2 * num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, test_labels)
plt.show()
最后,我们利用训练后的模型对单个图片进行预测。
img = test_images[0]
print(img.shape)(28, 28)TensorFlow的模型被优化从而可以一次性对一批或一组样本进行预测。因此,即使我们想要预测的是一张图片,我们也需要将它添加到列表中:
img = (np.expand_dims(img, 0))
print(img.shape)(1, 28, 28)现在,我们可以预测这张图片的正确标签了:
predictions_single = model.predict(img)
print(predictions_single)[[1.9848956e-07 6.2967965e-06 1.2487935e-07 4.5386710e-06 1.3287057e-06
3.8301427e-02 5.6206505e-07 6.0179342e-02 6.4673003e-07 9.0150553e-01]]plot_value_array(0, predictions_single, test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)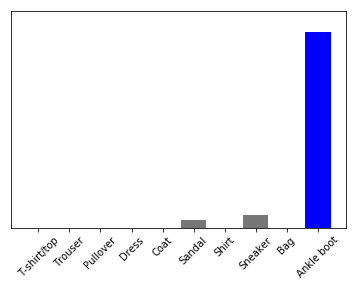
predict函数返回一个列表的列表——其中一个列表对应批次数据中的一个图片。
如下,获取我们所预测(单个)的图片的预测结果:
np.argmax(predictions_single[0])9和之前一样,该模型预测的标签为9。
本文完整代码请参考这里。



